






“ 你们看到的世界杯,其实都是录播的。你们想想,大晚上的哪来的太阳!”
今天我们来扯一扯,如何用一个简单的机器学习模型,预测世界杯比赛的结果。
01 问题定义
为了预测比赛胜负,我们需要将预测胜负的问题,进行一个合理的数学建模。
正常来说,一场足球比赛只可能有三种结果,即胜、负、平,在这种情况下,我们可以将预测胜负的问题定义为一个分类问题,即给定一场比赛的对阵双方,预测比赛结果属于胜、负、平三种的哪一类。
在机器学习中,分类问题可以定义为,利用一组已知的样本输入 X 和对应的类别 Y,构建一个分类器,预测一个未知样本 x 对应的类别。
从这个定义我们可以看出,在预测比赛胜负之前,我们需要一些已知样本来构建一个分类器,这组已知的样本,通常被称为训练集,需要预测结果的样本,通常被称为测试集。
对于世界杯预测的问题,我们已经有了一组需要预测结果的比赛,这些比赛就构成了我们的测试集。但是,我们还没有训练集,还不能构建分类器进行预测。
02 数据收集
为了构建分类器,我们需要收集一个训练集。
一般来说,当训练集和测试集的分布比较接近时,我们能得到一些比较靠谱的结果。
对于世界杯比赛,可以用以前世界杯比赛的数据作为训练集。不过,一届世界杯才64场比赛,这样的数据实在是太少,在数据较少的情况下,得到的分类器通常效果较差,预测的很不靠谱。为此,我们需要收集一些额外的数据进行补充。
对于额外数据的选择,我们从以下两方面出发进行考虑。
第一,世界杯比赛是成年国家队之间的比赛,因此,我们应该补充一些成年国家队之间的比赛,如大型杯赛,友谊赛等;像联赛和青少年比赛的数据,由于分布不同,所以不太适合作为训练集。
第二,足球比赛规则和战术流派在不断变化,用20年前的比赛结果预测现在的世界杯,分布差异太大,可能也不太靠谱。
基于上述两方面考虑,我们的训练集采用以下数据:14年、18年世界杯预选赛14年世界杯12年、16年欧洲杯16年欧洲杯预选赛15年、16年美洲杯13年、17年联合会杯15年、17年中北美金杯17年非洲杯15年亚洲杯17年、18年国家队友谊赛
为了获得这些数据,我们从一个专业的足球数据网站:http://whoscored.com,利用爬虫拿到了这些比赛的时间、结果、双方的出场球员以及球员的相关统计数据。
这些数据大约有2000场左右。
03 特征选择
有了训练集的数据,我们需要构造一些简单的特征,对比赛结果进行预测。这些特征,应该与比赛结果比较相关。
首先,比赛球队本身就是一个很好的特征,当我们听说比赛的队伍是巴西队和中国队的时候,不用想出场的球员是谁,十有八九就能预测中国队不太行。
接着,上场球员实力也是一个不错的特征,阿根廷踢德国的比赛,如果梅西不上,可能大家也不太会看好阿根廷。
再来,球队的板凳深度应该也是一个有用的特征,能在欧冠决赛把贝尔按在替补席上的皇马,获胜也在情理之中。
那么,综合以上想法,我们的特征其实就不难想象:两组ID特征:球队1的ID,球队2的ID球队1首发球员当年在联赛的平均数据球队1替补球员当年在联赛的平均数据球队2首发球员当年在联赛的平均数据球队2替补球员当年在联赛的平均数据
对于球员,其平均统计数据有13组,分别是:身高、体重、出场次数、助攻数、进球数、传球成功率、射门数、争顶头球成功率、最佳球员次数、出场时间、替补次数、赛后评分、排名。
在处理特征过程中,对于一些特别弱的国家,其比赛和球员数据可能有所缺失,为此,我们去掉了一些数据完全缺失的比赛,以免对预测结果产生影响。
04 模型训练
有了特征,我们就可以用模型构造一个分类器进行训练。
由于我们的训练数据只有2000条左右,为了丰富数据量,我们做了一个简单的数据扩展,即将球队1和球队2的特征互换,得到一条新数据,这样我们就将训练集从2000条扩展到了4000条。
在模型的选择上,由于数据量和数据维度不大,一些传统分类算法就能取得不错的效果。基于对效果的比较,我们最终选用了基于集成学习的AdaBoost算法,训练一个模型预测结果。
俗话说,三个臭皮匠,顶个诸葛亮。AdaBoost算法可以看成是多个弱分类器(这里用的是CART决策树)的集成。简单来说,AdaBoost先用一个弱分类器得到一组分类结果,然后根据这组结果,对出错的样本进行加权,得到下一个弱分类器。最后,通过对所有弱分类器的加权平均,我们能得到一组不错的结果。
在使用AdaBoost算法时,我们对球队ID进行了独热编码的处理,即将ID转化成了一个长度为N的单位向量(N是球队ID的总数)。
05 模型预测
训练好分类器后,我们可以对比赛的结果进行预测。
对于未知的比赛,由于我们不能提前知道世界杯比赛双方的首发阵容,因此,在预测时,我们只能用该队最近时间的一次比赛的数据进行模拟计算。
最终模型预测的结果如下: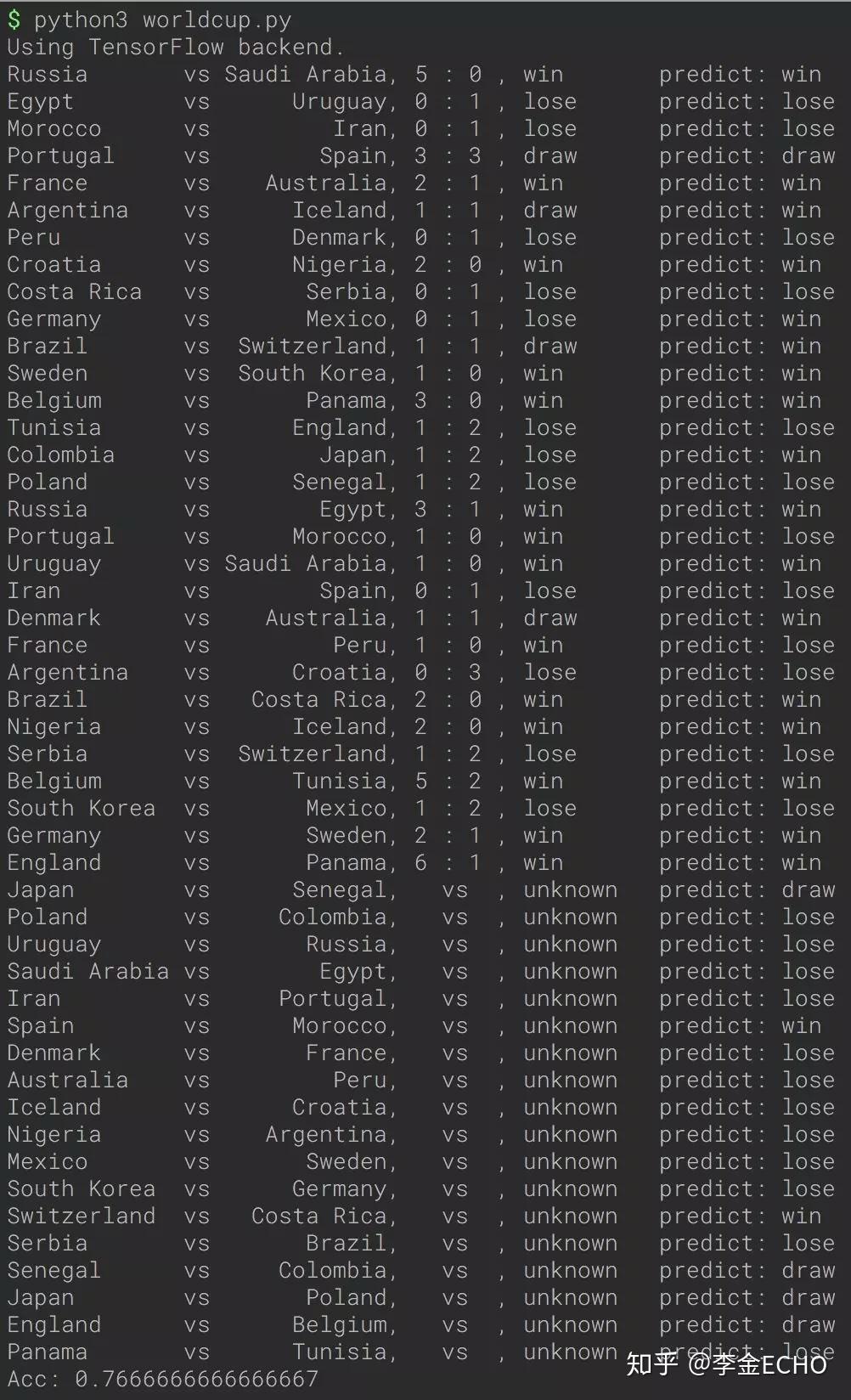
在日本与塞内加尔比赛前,该模型的准确率为0.767。
至于后面的比赛蒙的准不准,让我们拭目以待吧。
06 总结
本文纯属一本正经地胡说八道,对于预测结果的准确性,概不负责。
毕竟,足球是圆的,出现什么结果都是正常的!本导演说了也不算数啊!
“王秘书,给球员的盒饭准备好了吗?跟他们说,今天加鸡腿!”


版权声明
本文仅代表作者观点,不代表xx立场。
本文系作者授权xxx发表,未经许可,不得转载。

发表评论